오픈소스sw개론 Part 2, chap 5. NumPy (1)
1. NumPy란?
NumPy : Numerical Python
넘파이란 파이썬에서 수치적 계산을 하는 데에 기본적인 패키지 중 하나이다. 과학적 기능을 제공하는 대부분의 계산 패키지는 넘파이 배열 객체를 사용한다. 대규모 데이터 배열의 효율성을 위해 설계되었다.
NumPy의 특징
- ndarray : 빠른 배열지향 산술 연산과 유연한 broadcasting 기능을 제공하는 효율적인 다차원 배열이다.
- 데이터의 모든 배열에 대해, 빠른 수행을 위한 수학적 함수. loop를 작성할 필요가 없어서 빠른 연산이 가능하다.
- 선형대수 내용을 넘파이로 구현할 수 있다.
- C, C++, FORTRAN으로 작성된 라이브러리와 넘파이를 연결하는 A C API가 있다.
NumPy가 수치적 계산에 용이한 이유
- C로 쓰인 넘파이의 알고리즘 라이브러리는 유형 검사나 다른 overhead 없이 이 메모리에서 작동할 수 있다.
- overhead : 오버 헤드는 특정 기능을 수행하는데 드는 간접적인 시간, 메모리 등의 자원을 말한다.
- 넘파이 배열은 기존 파이썬 시퀀스에 비해 메모리 공간을 덜 사용한다.
- 넘파이는 loop 없이 복잡한 연산을 수행할 수 있다.
NumPy는 빠르다

넘파이 배열은 연산을 한 번에 하는 반면 리스트는 하나 하나 접근해 계산하므로 시간 차이가 난다.
2. NumPy의 ndarray
ndarray : n-dimensional array
ndarray는 넘파이 배열이자, n차원 배열이다. 파이썬의 대규모 데이터 셋을 위한 빠르고 유연한 컨테이너이다.

NumPy batch computation : 전체 데이터 블록을 한 번에 연산

동종 데이터에 대한 다차원 컨테이너
ndarray는 동종 데이터에 대한 포괄적인 다차원 컨테이너이다. 즉, 같은 타입 데이터만 다룰 수 있다.

3. ndarray의 생성
array 함수의 이용


zeros, empty, arange
- zeros를 이용해 주어진 형태의, 전부 0으로 초기화 된 배열을 만들 수 있다.
- empty를 이용해 특정한 값으로 초기화하지 않은, 비어있는 배열을 만들 수 있다.
- arange를 이용해 파이썬의 내장된 range 함수의 array-valued 버전을 구현할 수 있다.


추가적인 array 생성 함수들
- ones : zeros와 유사하나, 1로 초기화한다.
- full : zeros와 유사하나, 임의의 설정값인 fill value로 초기화한다.
- identity : N by N identity matrix를 생성한다.
4. ndarray의 데이터 형
dtypendarray의 데이터 형을 의미한다. metadata의 일종이다. (metadata란, 데이터를 설명하는 데이터를 말한다.)

NumPy 데이터 형
float16, float32, float64, float128, complex64, complex128, complex256 등 실수 관련 자료형이 매우 세분화되어 있다.
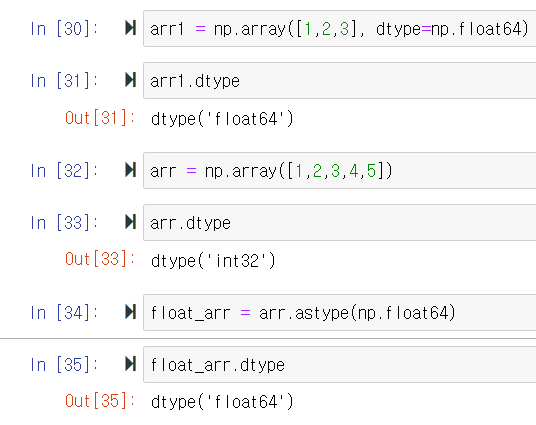
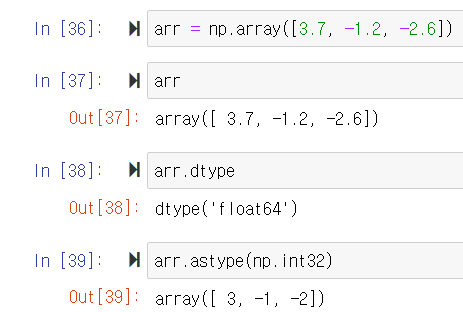
astype
한 dtype에서 다른 dtype으로 형태를 변환하는 함수이다.

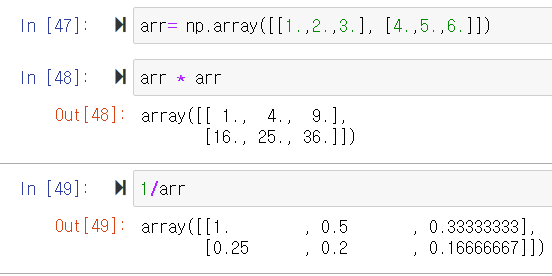
5. NumPy 배열을 이용한 산수
vectorization (벡터화)
numpy 배열은 for loop를 작성하지 않고도 데이터에 대한 batch 작업을 표현할 수 있기 때문에 중요하다. (batch 작업 : 데이터를 실시간으로 처리하는 것이 아니라, 일괄적으로 모아서 한 번에 처리하는 작업을 의미한다.)
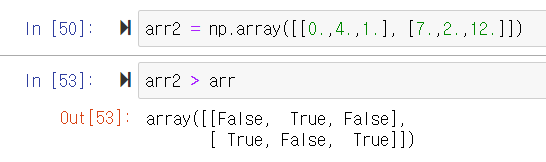
broadcasting
- 기본 개념 : 행렬에서의 broadcasting이란 작은 행렬을 크기가 큰 행렬 shape에 맞게끔 늘려주는 것을 말한다. 즉, shape이 다른 두 배열 사이 산수를 수행하면 broadcasting이 발생한다.

- demeaned(편차) : 배열의 각 열에서 열 평균을 빼서 각 열을 평균화한다.
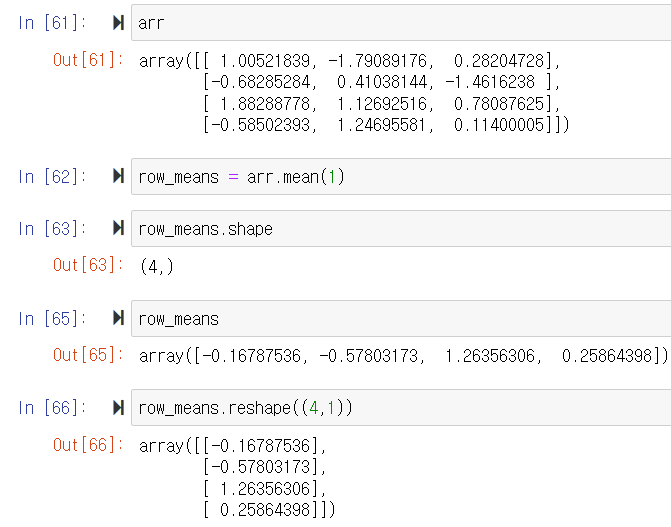
- arr.mean(0)은 column(열)의 평균을 구하는 것이다. row(행)의 평균을 구하고 싶으면 arr.mean(1)을 하면 된다.
- arr - arr.mean(0)은 2차원 배열에서 1차원 배열을 빼는 것으로, 1차원 배열 arr.mean(0)이 broadcast된다.
- demeaned.mean(0)은 편차의 평균을 의미하고, 이는 무조건 0이다. 아래 사진의 세 수는 0과 가까운 아주 작은 값이다.
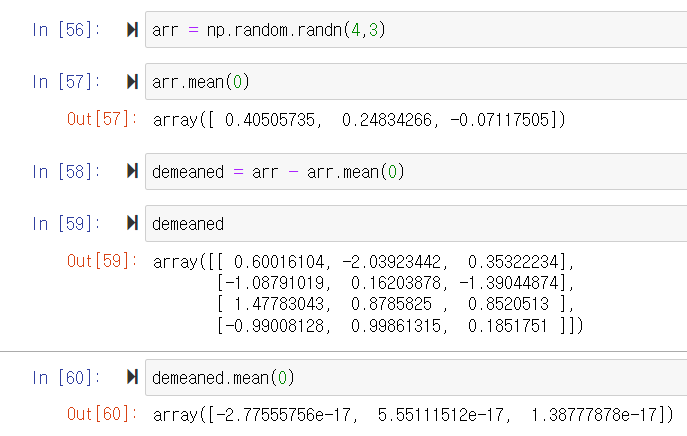
- mean과 reshape
- broadcasting은 3차원에도 동일하게 적용된다.
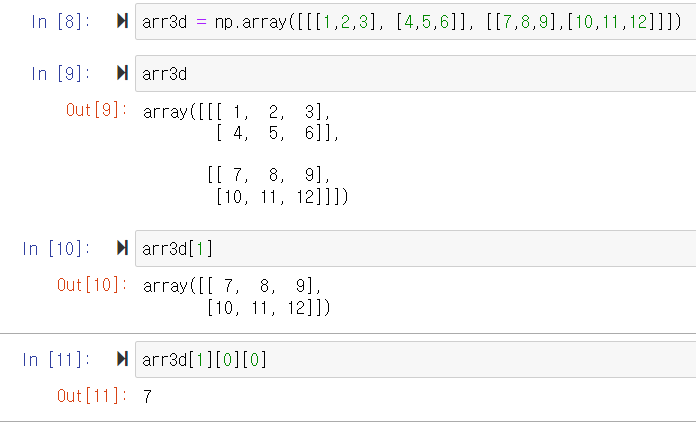
6. Indexing & Slicing
기본 동작
arr[x:y]를 통해 index x부터 y-1까지의 값을 얻을 수 있으며, arr[x:y] =n을 통해 x부터 y-1까지의 값을 n으로 설정할 수 있다.

배열의 slice는 원본 배열을 보여준다
- 배열을 slice해 값을 바꾸면 원본 배열이 바뀐다.

- slice는 배열의 모든 값에 할당된다.

2차원 배열
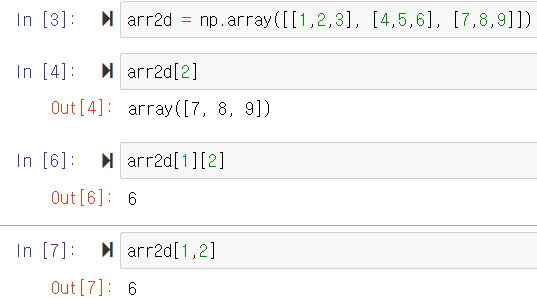
copy 함수

2차원 배열과 slice
row(행)에 대해 먼저 slicing하고, column(열)에 대한 slicing을 진행한다.

7. Boolean Indexing
string 배열로 인덱싱한 데이터의 boolean 접근
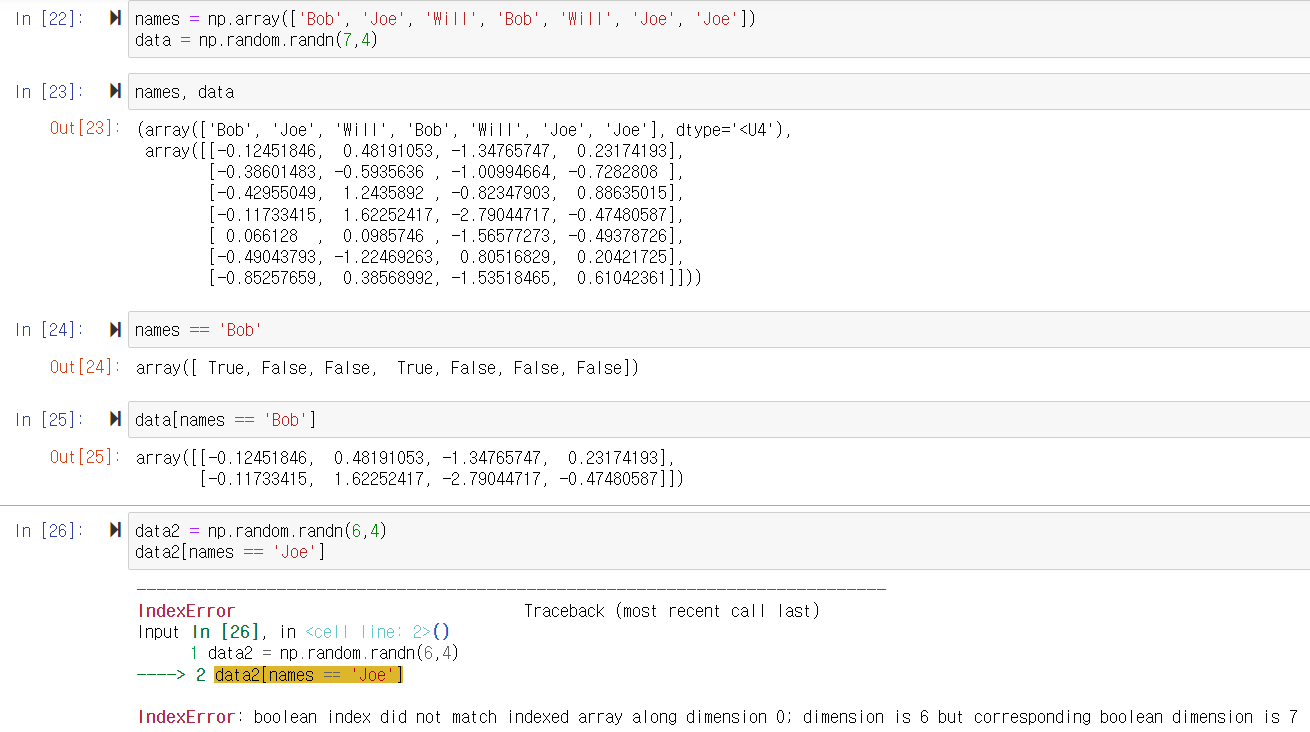
slicing, indexing을 이용한 추출
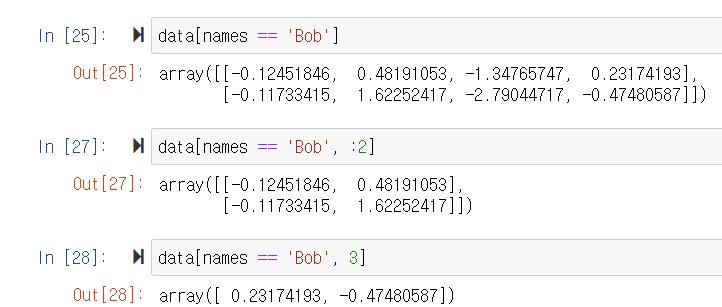
연산 기호의 사용
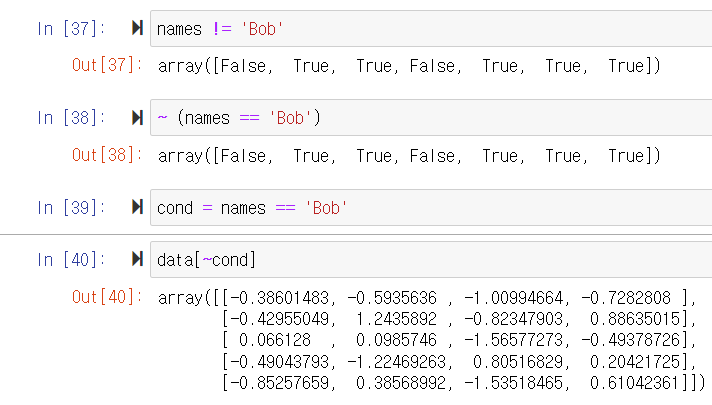
특정 부분을, 특정 값으로 초기화
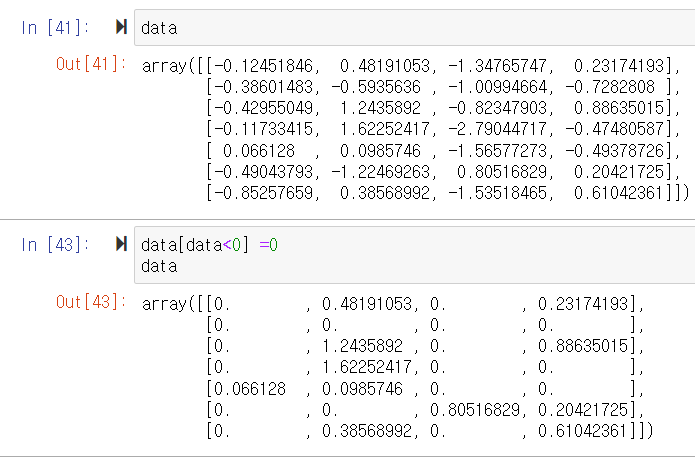
8. Fancy Indexing
Fancy Indexing이란?
NumPy에서 정수 배열을 사용한 인덱싱을 설명하는 용어다.
Fancy Indexing을 이용한 배열의 원소 접근
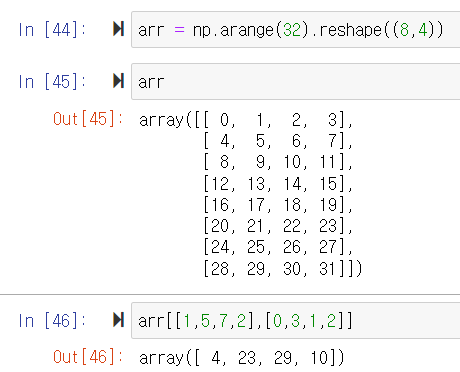
Fancy Indexing을 이용한 원소의 순서 변경
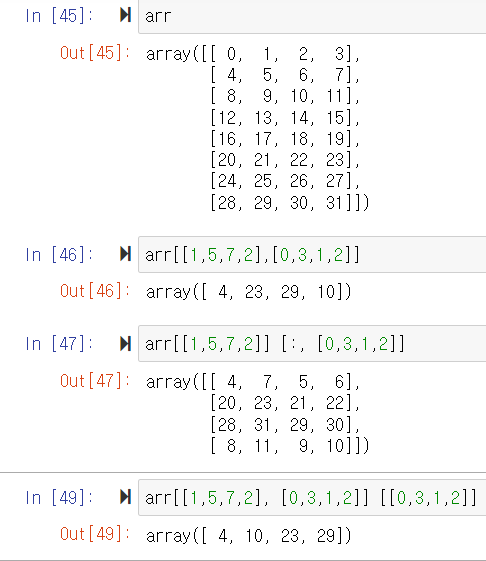
9. Transposing arrays and Swapping axes (배열 전치와 축 바꾸기)
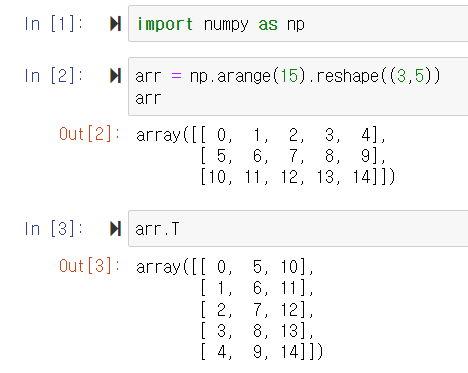
배열 전치 - T 속성
NumPy에는 transpose라는 함수가 있으며, 특별한 T 속성이 있다. 이 둘을 통해 배열 전치를 수행할 수 있다. T 속성은 2차원 배열에서만 사용 가능하다.
배열 전치 - transpose 함수와 swapaxes 함수
transpose와 swapaxes는 유사하다. 두 함수 모두, 두 함수를 통해 전해진 인자 값으로 reshape의 인자 순서가 바뀐다. transpose의 경우 인자를 '인덱스 순서'로 보면 되고, swapaxes의 경우 인자를 '지정 두 축의 바꾸기'로 보면 된다.


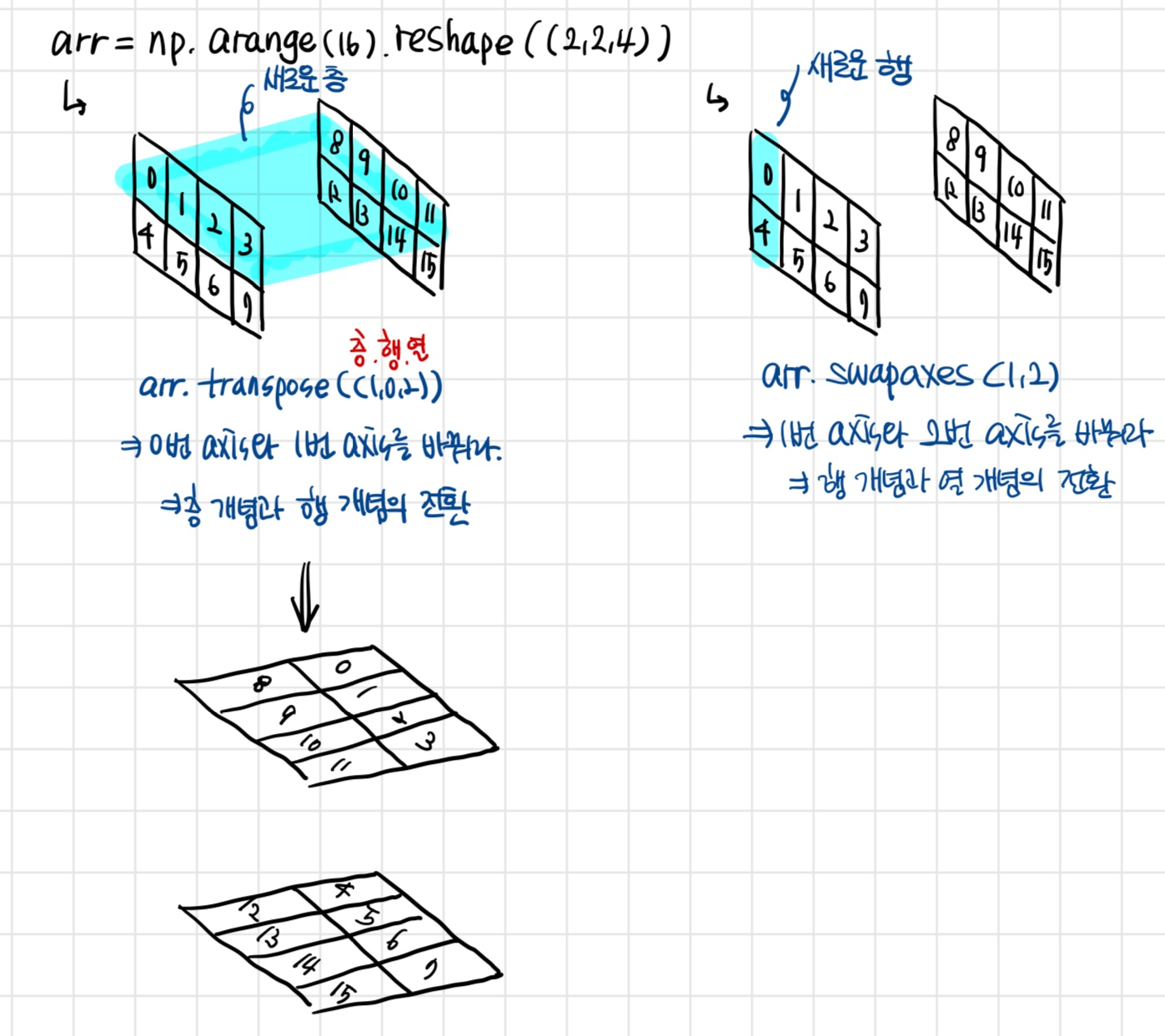
9-1. (추가) 축 개념 정복을 통한 전치의 이해
축 개념 정복
축은, 가장 바깥 리스트에서부터 안쪽 리스트로 가며 0부터 이름을 붙인다.
예를 들어, [ [ [1,2], [3,4] ], [ [5,6], [7,8] ] ]에 대하여
- axis 0은 [ [ [1,2], [3,4] ] / [ [5,6], [7,8] ] ]
- axis 1은 [1,2] / [3,4] 그리고 [5,6] / [7,8]
- axis 2는 1/2 그리고 3/4 그리고 5/6 그리고 7/8
3차원에 한해서, 각각의 축이 '층', '행', '열'에 대응한다고 생각하면 쉽다. 각각이 층을 구성하는 원소들, 행을 구성하는 원소들, 열을 구성하는 원소들이다. 이 개념을 위의 예시에 적용해 시각화하면 다음과 같다.
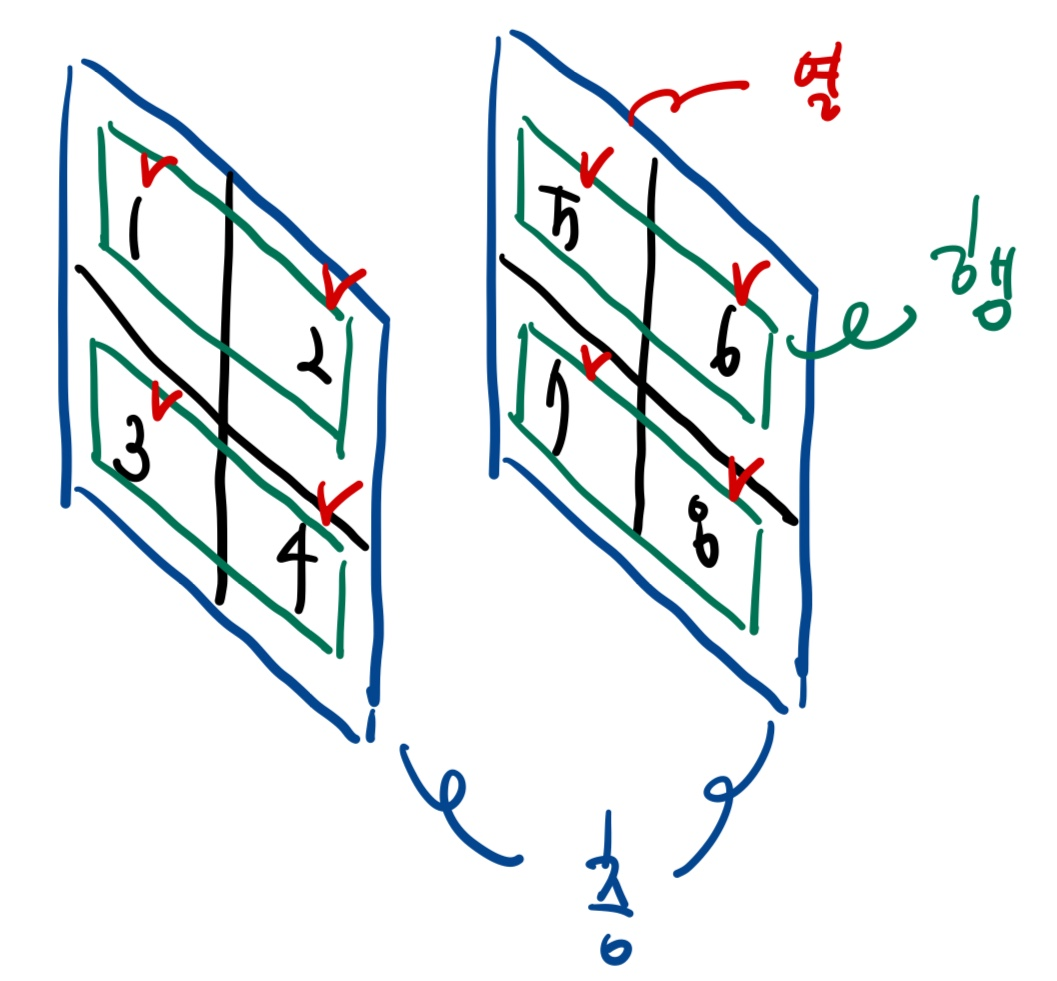
전치의 이해