2023. 12. 1. 17:20ㆍ컴퓨터공학 전공공부/오픈소스 SW개론
1. Universal Functions : 빠른 요소별 배열 함수
ufunc
보편적인 함수인 ufunc은 ndarray의 데이터에 대해 요소 단위 연산을 수행하는 함수이다. vectorization 연산을 지원한다.
unary ufunc
인자가 하나인 ufunc이다. sqrt (제곱근을 구하는 함수), exp (ex를 반환하는 함수) 등이 있다.

sqrt에 두 개의 같은 인자를 넣을 수 있는데, 이는 출력값으로 인자 배열을 초기화한다.
binary ufunc
인자를 두 개 받는 ufunc이다. maximum (인자로 들어온 두 배열을 요소 단위로 비교해서 큰 요소를 출력하는 함수) 등이 있다.
반환 값이 여러 개인 ufunc
ufunc은 여러 개의 배열을 반환할 수 있다. 예를 들어 modf 함수(첫 번째 반환 값으로 요소의 소수 부분을, 두 번째 반환 값으로 요소의 정수 부분을 반환하는 함수)가 있다.
2. 배열 지향 프로그래밍
값의 정규 그리드에 대한 sqrt 계산
grid(그리드)란, 행과 열로 이루어진 2차원 공간을 말한다.
2차원 배열에 대하여, graph library에 포함된 matplotlib을 이용하여 위의 결과를 시각화할 수 있다.
3. 조건 논리를 배열 연산으로 표현
numpy.where
조건문을 구현하는 함수의 벡터화 버전이다. 다시 말해, x if condition else y를 구현한다.
4. 수학적, 통계학적 함수
집계 기능의 함수 사용
sum, mean, std와 같은 집계 기능의 함수를 사용하려면 두 가지 방법 중 하나를 따른다. : 배열 인스턴스 메소드 호출, 상위 레벨의 NumPy 함수 사용
집계 기능의 함수와 축
- 0 : column(열) 연산, 모든 열의 '집계'
- 1 : row(행) 연산, 모든 행의 '집계'

집계 기능의 함수 - 누적합, 누적곱
cumsum()은 cumulative sum(누적합)을 구하는 함수이다. 2차원 배열에서 cumsum 메소드를 호출하면, cumsum의 인자로 축을 줄 수 있다. 위에서 설명한 것과 마찬가지로 0은 열 연산, 1은 행 연산이다. cumsum()과 비슷한 함수로 cumprod()가 있는데, 이는 누적곱을 구하는 함수이다.

주의할 점은, 열끼리의 누적합/곱 결과는 열로 나타난다. 다시 말해, 누적된 결과가 세로로 나타난다는 뜻이다. 아래 사진을 통해 이해하면 쉽다.

5. Boolean 배열을 위한 함수
sum
배열에 True가 몇 개 있는지 센다.

any, all
- any : 배열에 하나 이상 True가 있으면 True
- all : 배열이 전부 True면 True
6. 정렬
기본 정렬 (1차원 정렬)
NumPy의 sort 함수를 사용한다.

다차원 배열의 정렬
다차원 배열의 정렬 시 sort의 인자로 축을 넣어준다.

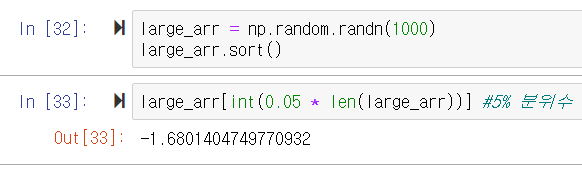
배열의 분위수 계산
7. Unique 로직과 다른 set 로직들
numpy.unique
np.unique(배열) 형태로 쓰이며, 중복값을 제거한 정렬된 배열을 반환한다. 순수한 파이썬 문법만 사용하여, sorted(set(배열))로 작성해도 동일한 결과가 나온다.

numpy.in1d
np.in1d(배열1, 배열2) 형태로 쓰인다. 배열 1의 각각의 원소에 접근하여 해당 원소가 배열 2에 포함되면 True를 반환한다. boolean 배열이 결과로 나온다.

8. 선형대수
행렬의 곱(내적)
dot 함수를 이용해 구현한다.

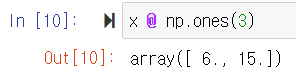
2차원 행렬과 1차원 행렬의 곱

2차원 행렬과 1차원 행렬의 곱을 계산할 때 @ 기호를 사용할 수 있으나, 지양하길 바란다.
numpy.linalg
numpy.linalg를 사용하면 선형대수 대부분을 구현할 수 있다. 이는 행렬 분해에 대한 표준 집합이다.
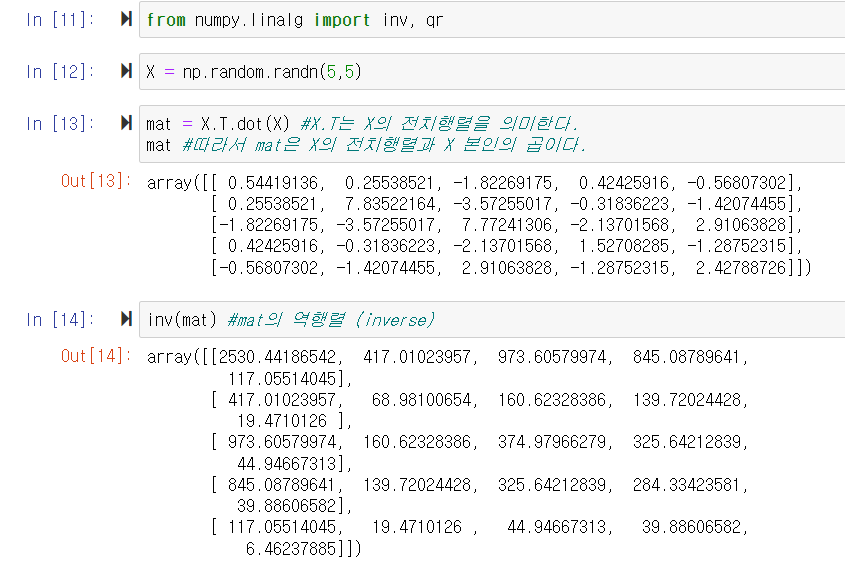

전치행렬과 역행렬 개념의 부연 설명을 덧붙인다. 전치행렬이란 기존 행렬의 행과 열을 서로 바꾼 행렬이다. 역행렬은 정방행렬 A에 대해 AB = BA = I (여기서 I는 단위행렬)를 만족하는 B가 존재하면, B를 역행렬이라고 한다.
QR 분해에 대해 간단한 부연 설명을 덧붙인다. 자세한 내용은 선형대수 개념을 깊게 알아야 하므로 간단하게만 짚고 넘어가도록 하자. q,r = qr(mat)이라는 코드를 통해 mat을 q와 r로 분해할 수 있으며, q는 직교행렬, r은 상삼각행렬이다. 직교행렬이란 모든 행 또는 열이 서로 직교하고 각 벡터의 크기가 1인 정사각 행렬이며, 상삼각행렬은 주대각선 아래의 모든 요소가 0인 정사각 행렬이다.
9. 유사 난수 생성
numpy.random
확률분포를 고려해 무작위의 값을 추출하는 함수이다. 파이썬에 내장된 random 모듈보다 훨씬 성능이 좋다.

numpy.random.normal()과 numpy.random.randn()
- numpy.random.normal()
- 기본적으로 표준 정규 분포 (평균 0, 표준편차 1)에 따라 난수를 생성하지만, 평균과 표준편차에 대한 추가적인 인자를 받아 그에 따른 난수를 생성할 수 있다.
- numpy.random.randn()
- 표준 정규 분포 (평균 0, 표준편차 1)에 따라 난수를 생성하며 평균과 표준편차를 바꿀 수 없다.
local state의 난수 추출
numpy.random의 함수는 기본적으로 전역 랜덤 시드를 사용한다. 지역 변수를 사용하고 싶다면, numpy.random.RandomState()를 사용하여 local 값으로 출력할 수 있다.

'컴퓨터공학 전공공부 > 오픈소스 SW개론' 카테고리의 다른 글
| 오픈소스sw개론 Part2, chap 7. Pandas (1) (2) | 2023.12.08 |
|---|---|
| 오픈소스sw개론 Part2, chap 6. NumPy Example, Random Walks (0) | 2023.12.01 |
| 오픈소스sw개론 Part 2, chap 5. NumPy (1) (2) | 2023.11.30 |