2023. 12. 7. 01:17ㆍ컴퓨터공학 전공공부/시스템 프로그래밍
1. Arrays (배열)
1-1. 배열의 정의
배열 할당
T A[L]의 꼴로 할당한다. (예를 들면, int A[10];) 이 경우 T라는 데이터 타입의, 길이 L인 배열을 할당한 것이다.
결국, T A[L]은 메모리 내에서 L * sizeof(T) 바이트의 연속적으로 할당된 영역이다.

배열 접근
int val[5]; 에 접근한다고 가정하자. val은 다음과 같은 메모리 공간을 가질 것이다.

이를 바탕으로 val에 다양하게 접근할 수 있다.
| Reference | Type | Value |
| val [4] //4번째 칸의 값에 접근 | int | 3 |
| val //시작점 (포인터)에 접근 | int * | x |
| val + i //자료형의 크기 * i만큼 주소 증가해 주소에 접근 |
int * | x + 4i |
| &val [2] //val[2]의 주소에 접근 | int * | x + 8 |
| val [5] //존재하지 않음 | int | ?? (error) |
| *(val + 1) //val | int | 5 |
배열 접근 예시


%rdi는 cmu 배열의 시작 주소를, %rsi는 배열의 인덱스를 담고 있다. z[digit]은 %rdi + 4*%rsi로 구할 수 있으며, 어셈블리 코드 형태로 표현하면 (%rdi, %rsi, 4)이다.
배열 접근 예시 문제

short는 2 바이트, long은 8 바이트라는 점을 짚고 시작한다.
P+3+i는 P+(3+i)로 볼 수 있고, 이는 자료형의 크기(2바이트) * (3+i)만큼 주소를 증가시켜 그 주소에 접근하는 것이다. 따라서 %rdx+6+2i를 어셈블리 코드 형태로 표현하면 6(%rdx, %rcx, 2)가 된다.
P[2]는 P의 두 번째 칸의 값에 접근하는 것이다. 따라서 %rdx + 4이고, 이를 어셈블리 코드 형태로 표현하면 4(%rdx)이다.
배열 loop 예시

1-2. 다차원 배열
다차원(중첩된) 배열
T A[R][C] 꼴로 할당한다. (예를 들면, int A[10][5];) T라는 타입이 K 바이트를 필요로 한다 했을 때, 배열의 크기는 R * C * K 바이트이다. 행(row)를 우선적으로 배치된다.

다차원 배열 예시

컴파일러는 20칸짜리 int가 필요하다고 판단하고 메모리를 할당할 것이다.
다차원 배열의 접근

A[i]가 C개의 원소를 가진 배열이라고 가정하자. 결론적으로, 특정한 행의 시작 주소는 A+(i*C*K)이다.
이전까지 C개의 원소를 가진 행이 i개 있었을 것이고, 각각이 K바이트만큼을 차지하므로 이전까지의 크기가 i*C*K가 된다. 여기에 맨 처음 시작 주소인 A를 더해 특정한 행의 시작 주소를 구한다.한편 A[i][j]에 접근하고 싶으면 현재 주소(시작 주소) A+(i*C*K)에 j*K를 더해주면 된다.
다차원 배열의 접근 코드
pgh[index]는 5개의 integer를 가지는 배열이다. pgh에서 특정한 행의 시작 주소는 pgh+20*(index)이다. (4byte*5개) 이를 얻는 C 코드와 어셈블리 코드는 다음과 같다.
//C code
int get_pgh_zip (int index) {
return pgh[index];
}
//assembly
//%rdi = index
leaq (%rdi, %rdi, 4), %rax //5*index
leaq pgh(,%rax,4), %rax //pgh + 20*index
//첨언 : pgh(,%rax,4)는 맨 앞의 base인자가 생략된 경우로, 4*%rax를 행한다.한편 pgh[index][dig]의 주소는 pgh+20*(index)+4*(dig)이다. 이를 얻는 C 코드와 어셈블리 코드는 다음과 같다.
//C code
int get_pgh_digit (int index, int dig) {
return pgh[index][dig];
}
//assembly
leaq (%rdi, %rdi, 4), %rax //5*index
addl %rax, %rsi //5*index+dig
movl pgh(,%rsi,4), %eax //M[pgh+4*(5*index+dig)]1-3. 다단계 배열
다단계 배열 예시
//C code
zip_dig cmu = {1,5,2,1,3};
zip_dig mit = {0,2,1,3,9};
zip_dig ucb = {9,4,7,2,0};
#define UCOUNT 3
int *univ[UCOUNT] = {mit, cmu, ucb}; //*univ 배열은 #3*8바이트 크기를 가진다.*univ 배열은 3개의 원소를 가지며, 각각의 원소는 8바이트짜리 포인터이다. 각각의 포인터는 integer 배열을 pointing한다.
위의 배열을 시각화하면 아래와 같다.

이 배열에서 특정한 원소의 값(즉, Mem[Mem[univ+8*index] +4*digit])을 읽으려면 두 단계를 거쳐야 한다.
- row(행) 주소에서 포인터를 읽는다.
- 배열에서 특정 원소에 접근한다.
이를 구현하는 코드는 다음과 같다.
//C code
int get_univ_digit (size_t index, size_t digit) {
return univ[index][digit];
}
//assembly
salq $2, %rsi //4*digit
addq univ(,%rdi,8), %rsi //p=univ[index] + 4*digit
movl (%rsi), %eax //return *p
ret1-4. 다차원 배열 vs 다단계 배열
배열의 접근 : 다차원 vs 다단계
다차원 배열에서 특정한 원소에 접근하려면 Mem[ pgh + 20*index + 4*digit ]의 과정을 거친다. 다단계 배열에서 특정한 원소에 접근하려면 Mem [ Mem [ univ + 8*index ] + 4*digit ]의 과정을 거친다. 다단계 배열이 두 번의 메모리 접근을 행하는 데에 비해 다차원 배열은 한 번만 행한다는 이점이 있지만, 배열의 크기가 늘어나면 책장이 너무 길어지기 때문에 (다단계 배열에 비해) 공간 효율이 낮다는 단점이 있다.
1-5. n x n 행렬
n x n 행렬 접근
n x n 행렬의 특정 원소에 접근하려면, A + i*(C*K) + j*K 주소에 접근하면 된다. 여기서 C는 n이며, K는 원소의 크기(ex. int = 4바이트)이다. 코드로 표현하면 다음과 같다.
//C code
//Get element a[i][j]
int var_ele(size_t n, int a[n][n], size_t i, size_t j) {
return a[i][j];
}
//assembly
//n in %rdi, a in %rsi, i in %rdx, j in %rcx
imulq %rdx, %rdi //n*i
leaq (%rsi, %rdi, 4), %rax //a + 4*n*i
movl (%rax, %rcx, 4), %eax //a + 4*n*i + 4*j
ret2. Structures (구조체)
2-1. 구조체의 정의
structure의 표현
structure란, 서로 다른 데이터형을 여러 개 모아 둔 것이다. 다음은 structure의 예시이다.
//C code
struct rec {
int a[4];
size_t i; //size_t란 시스템에서 쓰는 기본 데이터 크기를 말한다. 여기선 8바이트이다.
struct rec *next;
};이 경우, 다음과 같은 순서로 메모리에 저장된다.

sturcture 멤버에 대한 포인터 생성
아래 코드는 위의 rec을 이어받은 상태에서, structure 내의 배열 a의 idx번째 요소의 주소를 반환하는 함수이다. 결론적으로 r + 4*idx를 통해 해당 주소를 반환할 수 있다.
//C code
int *get_ap (struct rec *r, size_t idx) {
return &(r->a[idx]);
}
//assembly
//r in %rdi, idx in %rsi
leaq (%rdi, %rsi, 4), %rax //leaq src,dst : dst에 src를 저장한다. 이 때 src는 주소 형태이다.
//%rdi는 기본 주소이며, %rsi에 4를 곱한 값을 %rdi에 더해 새로운 주소를 얻는다.
ret위 코드에 대해 부연설명을 덧붙인다. get_ap 함수는 rec의 포인터 r과 인덱스 idx를 인자로 받아, r이 가리키는 structure 내의 배열 a의 idx번째 요소의 주소를 반환한다. 반환되는 주소는 int 타입의 포인터이다. get_ap의 동작을 다음과 같이 시각화할 수 있다.
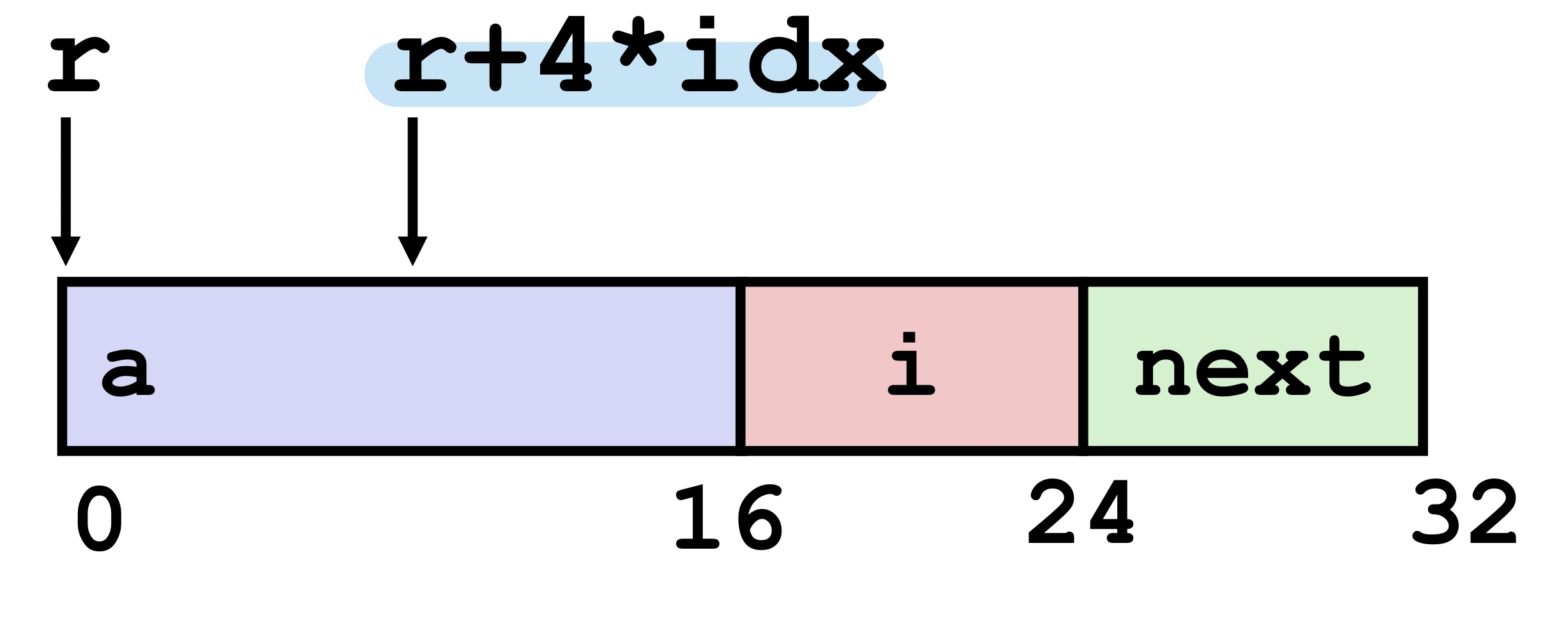
structure 예시 문제


quiz의 메모리 공간은 왼쪽과 같이 구성된다. 따라서 s안의 y에 접근, 즉 y의 시작주소에 접근하기 위해선, q에서 10만큼 이동해야 한다. 따라서 정답은 movl 10(%rdi), %ax이다.
2-2. 구조체의 정렬
structure와 정렬
struct S1 {
char c;
int i[2];
double v;
} *p;다음과 같은 structure S1이 있다고 해보자. 데이터를 정렬했을 경우와 정렬하지 않았을 경우, 메모리의 구성은 다음과 같다.


정렬할 때엔 다음과 같은 규칙을 따라야 한다. : 데이터는 시작 주소가 데이터 형의 배수인 주소에 할당되어야 한다. 이는 더 효율적으로 메모리를 관리하기 위해서이다. 이를 위해서 컴파일러는 메모리 사이 사이에 gap을 넣는다.
(참고) 자주 쓰는 데이터 형과 그 크기이다.
- 1바이트 : char
- 2바이트 : short
- 4바이트 : int, float
- 8바이트 : double, long, char*(포인터)
결론적으로, structure는 K의 배수만큼의 공간을 필요로 하게 된다. 여기서 K는 structure 안에서 가장 큰 원소의 크기이다. 따라서 structure를 구성할 때엔 원소의 크기가 큰 데이터를 앞에 놓는 것이 좋다.
2-3. 구조체 배열
structure의 배열
//C code
struct S3 {
short i;
float v;
short j;
} a[10];위와 같은 structure가 있을 때, S3의 메모리 공간은 다음과 같이 구성된다.

a[idx].j의 시작주소에 접근하기 위한 코드는 다음과 같다.
//C code
short get_j (int idx) {
return a[idx].j;
}
//assembly
//%rdi = idx
leaq (%rdi, %rdi, 2), %rax //3*idx
movzwl a+8(,%rax,4), %eax //a+8부분은 상수가 와야 할 자리인데, 변수가 오고 있다!
//이 경우 나중에 linking을 통해 상수 값이 들어간다.2-4. union을 통한 할당
union이란?
여러 데이터 형을 모은다는 점에서, 생김새는 structure와 유사하다. 한편 structure와 달리, 각각의 데이터 형에 메모리를 부여하지 않고 한 번에 부여한다.
//C code
union U1 {
char c;
int i[2];
double v;
} *up;이러한 U1에 대하여 메모리 공간은 아래와 같이 할당된다.

(추가) v=0으로 초기화된 상태에서 c에 접근하면 v의 앞부분을 따온다.
union을 이용하여 같은 값을 다양한 데이터 형으로 해석
//C code
typedef union {
float f; //4byte
unsigned u; //4byte. unsigned int와 같은 표현이다.
}
float bit2float (unsigned u) {
bit_float_t arg;
arg.u = u; //unsigned 형의 값을 할당한다.
return arg.f; //값은 그대로. 해석은 float로.
}
unsigned float2bit (float f) {
bit_float_t arg;
arg.f = f;
return arg.u; //마찬가지로 값은 그대로. 해석은 unsigned로.
}
union과 바이트 순서 지정
바이트 순서는 little endian 방법과 big endian 방법으로 나뉜다.


'컴퓨터공학 전공공부 > 시스템 프로그래밍' 카테고리의 다른 글
| 시스템 프로그래밍 chap 8. Process and Virtual Memory (2) | 2023.12.07 |
|---|---|
| 시스템 프로그래밍 chap 7. Linking (1) | 2023.12.07 |
| 시스템 프로그래밍 chap 5. Machine-Level 프로그래밍 과정 (2) | 2023.12.04 |